
Welcome to the internet home of Kingsley Torlowei. Data Scientist, Software Engineer.
Feel free to look around, check out my portfolio, or get in touch.
Welcome to the internet home of Kingsley Torlowei. Data Scientist, Software Engineer.
Feel free to look around, check out my portfolio, or get in touch.
In this project, we’ll attempt to summarize document that solidify Nigerias validity as a state, the Constitution. Our goal in this project is to implement a machine learning algorithm that takes in sentences of the our corpus (constitution) and outputs a summarsed text.
#Goal: create word vectors
from __future__ import absolute_import, division, print_function
#for word encoding
import codecs
#regex
#import glob
#concurrency
import multiprocessing
import os
import pprint
import re
import nltk
import gensim
import sklearn.manifold
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
#currdir = os.path.dirname(__file__)
f = open('constitution.txt', 'r')
text = f.read()
We preprocess by calling the nltk library which will be used to remove stop words and splitting the text file into sentences as we’ll see later in this post
#process and clean data
nltk.download('punkt') #pretained tokenizer
nltk.download('stopwords') #words like and, or, an, a
[nltk_data] Downloading package punkt to
[nltk_data] /Users/kingsleytorlowei/nltk_data...
[nltk_data] Package punkt is already up-to-date!
[nltk_data] Downloading package stopwords to
[nltk_data] /Users/kingsleytorlowei/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
True
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
#Split the text file into sentences
raw_sentences = tokenizer.tokenize(text)
print(raw_sentences[1])
(1) This Constitution is supreme and its provisions shall have binding force on the authorities and persons throughout the Federal Republic of Nigeria.
#converting the constitution to a list of words
def sentence_to_wordList(textFile):
words = re.sub("[^\w]", " ", textFile).split()
return words
#create an instance where for every sentense, each word is tokenized
sentence = []
for raw_sentence in raw_sentences:
sentence.append(sentence_to_wordList(raw_sentence))
print(raw_sentences[5])
print(sentence[5])
(1) Nigeria is one indivisible and indissoluble sovereign state to be known by the name of the Federal Republic of Nigeria.
['1', 'Nigeria', 'is', 'one', 'indivisible', 'and', 'indissoluble', 'sovereign', 'state', 'to', 'be', 'known', 'by', 'the', 'name', 'of', 'the', 'Federal', 'Republic', 'of', 'Nigeria']
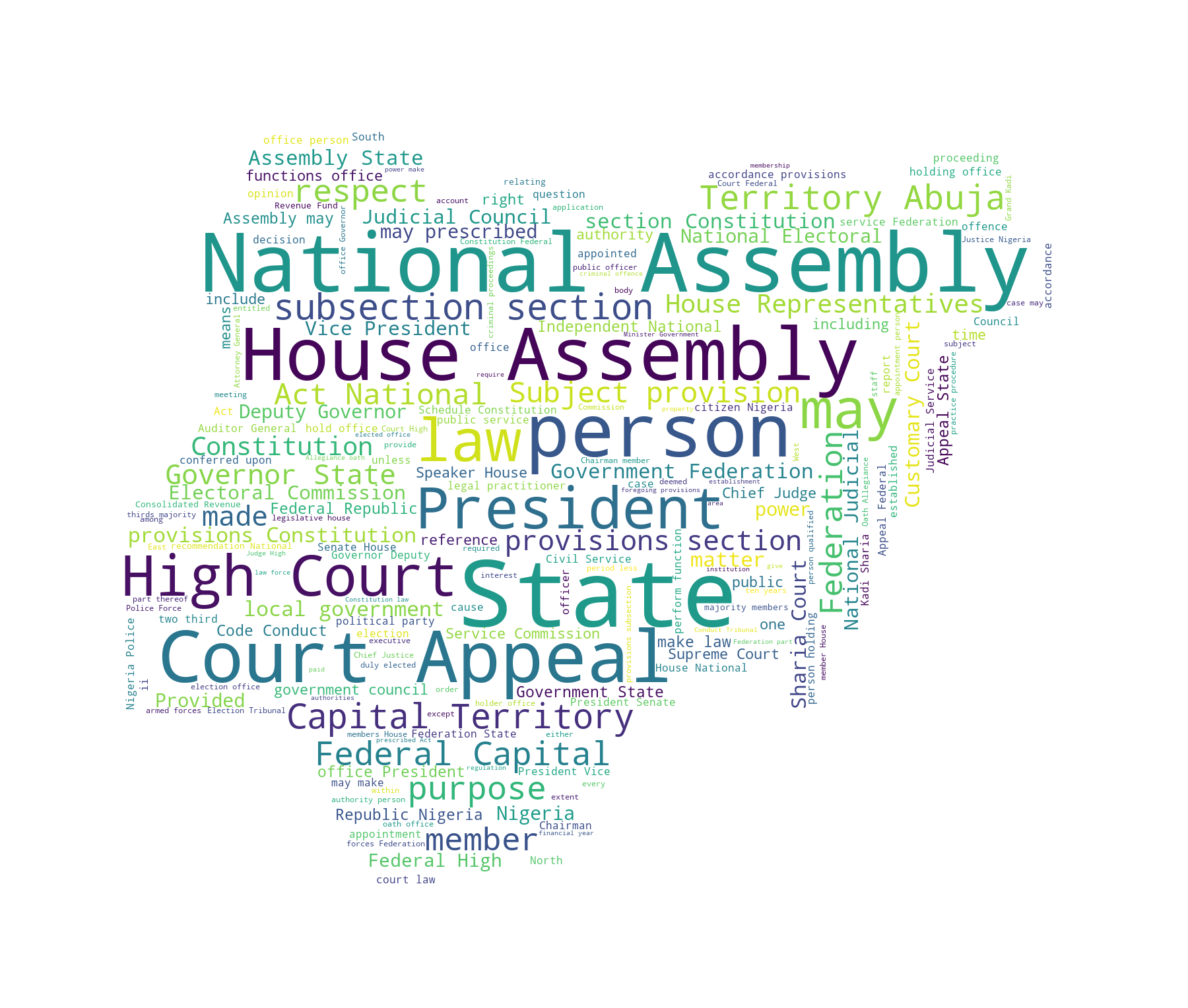
Now let’s create a wordcloud to capture the most used words (minus stopwords) in the constitution
import sys
from os import path
import numpy as np
from PIL import Image
from wordcloud import WordCloud, STOPWORDS
# get path to script's directory
#currdir = path.dirname(__file__)
def create_wordcloud(text_file):
# create numpy araay for wordcloud mask image
#mask = np.array(Image.open(path.join(currdir, "cloud.png")))
mask = np.array(Image.open("cloud.png"))
# create set of stopwords
stopwords = set(STOPWORDS)
# create wordcloud object
wc = WordCloud(background_color="white",
max_words=200,
mask=mask,
stopwords=stopwords)
# generate wordcloud
wc.generate(text)
# save wordcloud
wc.to_file("wc.png")
if __name__ == "__main__":
# generate wordcloud
create_wordcloud(text)
from IPython.display import Image
Image("wc.png")
Train Word2Vec
#vectors help with Distance, Similarity and Ranking of Words
#the more features with have, the accurate our model gets but also the more expensive to train
num_features = 1000
min_word_count = 2
#more workers, the faster we train
num_workers = multiprocessing.cpu_count()
#Size of words to look at, at a time
context_size = 7
#Downsample setting for frequent words
downsampling = 1e-3
#Seed, random number generator, good for debugging
seed = 1
model = gensim.models.Word2Vec(sg=1, seed=seed, workers=num_workers, size=num_features, min_count = min_word_count, window=context_size, sample= downsampling)
model.build_vocab(sentence)
model.train(sentence, total_examples=len(sentence), epochs= 10)
(388950, 642700)
model.most_similar("constitution")
/anaconda3/lib/python3.6/site-packages/ipykernel_launcher.py:1: DeprecationWarning: Call to deprecated `most_similar` (Method will be removed in 4.0.0, use self.wv.most_similar() instead).
"""Entry point for launching an IPython kernel.
/anaconda3/lib/python3.6/site-packages/gensim/matutils.py:737: FutureWarning: Conversion of the second argument of issubdtype from `int` to `np.signedinteger` is deprecated. In future, it will be treated as `np.int64 == np.dtype(int).type`.
if np.issubdtype(vec.dtype, np.int):
[('interpretation', 0.9279025793075562),
('refers', 0.9160458445549011),
('299', 0.9070886373519897),
('referred', 0.9006040096282959),
('arises', 0.8977278470993042),
('appellate', 0.8947620391845703),
('236', 0.8901001214981079),
('IV', 0.8864456415176392),
('schedule', 0.8862982988357544),
('advance', 0.8850321173667908)]
model.most_similar('Commander')
/anaconda3/lib/python3.6/site-packages/ipykernel_launcher.py:1: DeprecationWarning: Call to deprecated `most_similar` (Method will be removed in 4.0.0, use self.wv.most_similar() instead).
"""Entry point for launching an IPython kernel.
/anaconda3/lib/python3.6/site-packages/gensim/matutils.py:737: FutureWarning: Conversion of the second argument of issubdtype from `int` to `np.signedinteger` is deprecated. In future, it will be treated as `np.int64 == np.dtype(int).type`.
if np.issubdtype(vec.dtype, np.int):
[('Officer', 0.9789463877677917),
('Ambassador', 0.9775965213775635),
('Magistrate', 0.9735214710235596),
('Each', 0.9718083739280701),
('audited', 0.9702088236808777),
('Chairmen', 0.9684798717498779),
('Principal', 0.9675396680831909),
('Resident', 0.9624351263046265),
('Armed', 0.9602147340774536),
('headquarters', 0.9597746133804321)]